AWS OpenSearch, NestJS, RabbitMQ, Prisma, MySQL
Search Infrastructure R&D — Zero-Downtime Reindex
R&D effort for Nights Plus (PaintNite) — diagnosed that production search downtime was caused by the reindex implementation, not the search engine, and built a zero-downtime reindex pipeline without any infrastructure migration or additional cost.
What needed to be solved
The Nights Plus platform (PaintNite) was experiencing production downtime every time a search index schema change was needed — adding a new filterable field, changing a mapping — a full reindex would take the index offline for its entire duration. There was no rollback path if it failed mid-run, and the process required manual steps in the AWS console. The assumption was that the search engine itself was the problem.
Key Decisions & Challenges
Stay on AWS OpenSearch vs Migrate to Algolia, Typesense, or Serverless
Situation
The platform assumed the search engine was causing the downtime. Four alternatives were formally evaluated across pricing, geo search, typo tolerance, alias-swap support, auto-scaling, and operational overhead before drawing any conclusions.
Options Considered
- Algolia — dropped, unpredictable cost at scale
- Typesense — capable, but new infrastructure and cost without sufficient justification
- AWS OpenSearch Serverless — dropped, $525/month floor unjustified at current scale
- Elastic Cloud Serverless — dropped, existing managed clusters were already sufficient
Decision
Stayed on the existing AWS OpenSearch managed clusters. The investigation found that the downtime was caused by the reindex implementation — no alias management, no automated rollover, manual AWS console steps, no resume path on failure. OpenSearch has supported alias-swap reindexing since v1.0. The existing clusters already had everything needed. The fix was an implementation change, not a platform migration.
Alias-Swap Pattern for Zero-Downtime Schema Changes
Situation
The existing approach rewrote the live index in place, taking it offline for the entire duration of the rebuild. Any schema change meant downtime. If the process failed mid-run, there was no rollback path.
Options Considered
- Continue with in-place reindex — simple, but causes downtime and has no rollback
- Alias-swap — build the new versioned index in the background while the old stays live, then swap atomically on completion
Decision
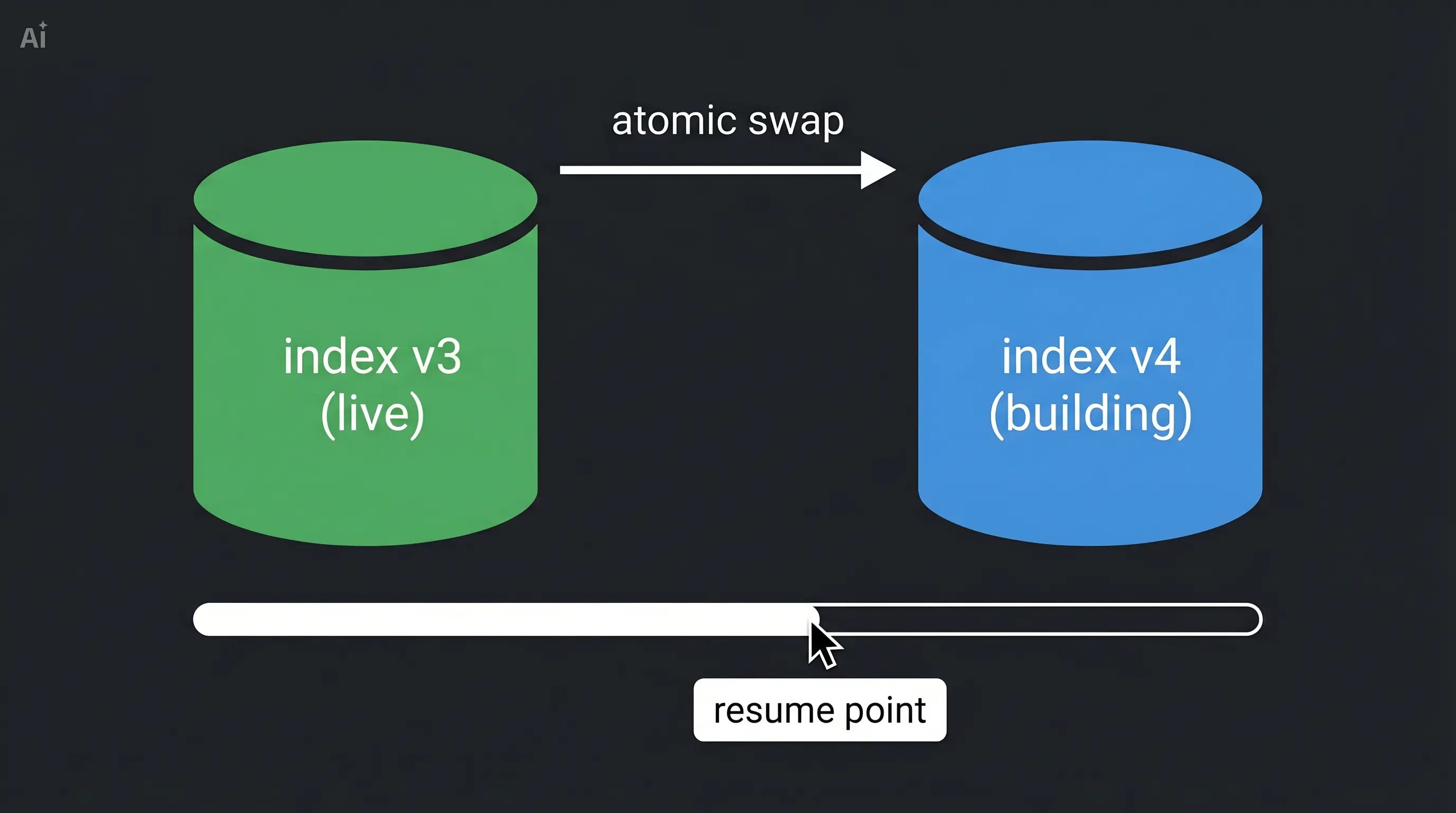
Implemented the alias-swap pattern. All search queries go through an alias name, never directly to a versioned index. A new versioned index (e.g. events_v4) builds in the background while events_v3 stays live and serves all traffic. The swap is a single atomic operation on OpenSearch — no window where the alias points nowhere. If the new index fails to build, the old index stays live with no impact on users.
Cursor-Based Resume vs Restart on Crash
Situation
A full reindex can run for a long time. If the service crashes or is redeployed mid-job, the question is whether the job restarts from scratch or can resume where it stopped.
Options Considered
- Restart from scratch on any crash — stateless, simple, but wastes work and can loop if the crash is consistent
- Cursor-based resume — persist the last processed row ID to the database and resume from exactly there on restart
Decision
Cursor-based resume. All reindex job state is persisted in MySQL — current phase (backfill, alias swap, cleanup), documents processed so far, and the last processed row ID. If the service crashes at any point, the next startup reads the job record and resumes without re-processing any already-indexed documents. Crash recovery behaviour is also phase-aware: a crash during alias swap checks whether the swap already completed before re-attempting it; a crash during cleanup retries deletion safely since deleting an already-deleted index is treated as success.
Dual-Write to Keep the New Index Current During Backfill
Situation
A backfill can run for minutes or longer. During that time, live data keeps changing — new bookings, event updates, venue changes. Without a strategy, the new index could hold stale versions of recently updated documents once they are overwritten by their batch entry.
Options Considered
- Pause live writes during reindex — eliminates the staleness problem but causes write downtime
- Re-index all changed documents at the end — adds complexity and still has a race window
- Dual-write — for every live update, write to both the current live index and the new index being built simultaneously
Decision
Dual-write. Every real-time update writes to both the live index and the new index throughout the backfill. If the dual-write to the new index fails, the error is logged and the backfill loop self-heals — when the batch loop reaches that document's row ID, it writes the correct version from the database. The live index write is never affected by dual-write failures.
Features
Drift Detection on Every Deployment
On every startup, the application compares the index mapping defined in code against the live index on OpenSearch. If they differ, a background reindex starts automatically — no developer intervention required for standard schema changes.
Alias-Swap with Zero Downtime
New index versions build in the background while the live alias continues serving all search traffic. The swap is atomic — no window where the alias points nowhere. The old index is deleted after the swap completes.
Cursor-Based Resume After Any Crash
All job state is persisted in MySQL. Crashes at any phase — backfill, alias swap, or cleanup — are handled with the correct recovery action. The job resumes from the exact row it stopped at, with no documents re-processed unnecessarily.
Dual-Write During Backfill
Live updates write to both the current live index and the new index being built. Dual-write failures are self-healing — the backfill loop overwrites with fresh data from the database when it reaches that row.
Three Reindex Triggers
Automatic (drift detected on deployment), scheduled (AWS EventBridge → Lambda on a configurable interval, e.g. every 3 hours to catch any documents missed by real-time sync), and manual (via API or the super admin panel for targeted fixes).
Concurrency Control
A maximum of 2 reindex jobs run simultaneously to prevent overwhelming the database or OpenSearch. Additional jobs queue as pending and are picked up event-driven when a slot frees, with an EventBridge safety-net timer to prevent stuck queues.
Error Handling with Auto-Resume
Errors during backfill trigger up to 3 retries before the job pauses. A recovery check runs every 30 seconds — once connectivity is restored, the job resumes automatically. Jobs paused for more than 30 minutes are marked failed and logged to CloudWatch.
Super Admin Panel Controls
UI controls for triggering full or partial reindexes (by specific record IDs), viewing live job status (phase, documents processed, errors), and managing the reindex schedule per index — all without requiring developer API calls.
My Role
I was the sole developer and architect on this project — conducting the four-way service evaluation, designing the reindex pipeline and state machine, and implementing the full NestJS microservice. The implementation made extensive use of Claude Code for code generation, with my focus on the architectural decisions, the state machine design, and careful review of the generated pipeline logic.
Tech Stack
Outcome
Zero additional infrastructure cost. Zero migration risk. Schema changes that previously required manual AWS console steps and took production offline now trigger a background reindex automatically on deployment, resume after any crash, and complete with zero downtime. The implementation is complete and will go live as part of the broader Nights Plus platform rebuild.